이 장에서는 실행 계획에 대한 소개, SQL 커멘드의 EXPLAIN PLAN를 해설하고, 그 출력의 해석 방법을 설명합니다. 또한 어플리케이션의 퍼포먼스 특성을 제어하는 OUT LINE 을 관리하는 프로시저에 대해 알아 봅니다.
이 장은 다음의 순서로 진행됩니다.
■ EXPLAIN PLAN 에 대해
■ PLAN_TABLE 출력표의 작성
■ EXPLAIN PLAN 의 실행
■ PLAN_TABLE 출력의 표시
—————————————————————
■ EXPLAIN PLAN 에 대해
—————————————————————
EXPLAIN PLAN 문은 SELECT, UPDATE, INSERT 및 DELETE 문에 대해 Oracle 옵티마이져가 선택한 실행 계획을 표시합니다. 문장의 실행 계획이란 Oracle이 그 문장을 실행하기 위해 실시하는 일련의 처리입니다.
행 소스·트리는, 실행 계획의 핵심입니다.행 소스·트리는 다음의 정보를 나타냅니다.
문장에 의해 참조되는 테이블의 순서
문장으로 언급되는 각 테이블에의 액세스 방법
문장의 결합 조작의 영향을 받는 테이블의 결합 방법
필터, 소트, 집계등의 데이터 조작
PLAN TABLE 에는, 행 소스·트리의 외, 다음의 정보가 포함되어 있습니다.
최적화.각 조작의 코스트와 카디나리티에 대해
파티션화.액세스 된 파티션세트 등
패러렐 실행.결합 입력의 배분 방법 등
EXPLAIN PLAN의 결과에 의해 옵티마이져가 특정의 실행 계획(예를 들어 nested·루프 결합)을 선택할지를 판단할 수 있습니다. 또, 옵티마이져의 결정(예를 들어 옵티마이져가 해시 결합이 아니고 nested·루프 결합을 선택한 이유)에 대한 이해 등 퍼포먼스를 알기 위해서 도움이 된다.
실행 계획의 변하는 이유
———————–
코스트 베이스· 옵티마이져를 사용하면 실행 계획은 기초가 되는 코스트가 변화할 때에 변화합니다. EXPLAIN PLAN 의 출력은 SQL 문의 설명 단계에서의 실행 방법을 나타냅니다.이 방법은 실행 환경과 EXPLAIN PLAN 환경과의 차이에 의해 SQL 문의 실제의 실행 계획과는 다른 경우가 있습니다.
실행 계획은 다음의 이유에 의해 다릅니다.
1. schema의 서로 틀림
——————–
1. 실행과 EXPLAIN PLAN이 다른 데이타베이스상에서 일어나는 경우.
2. 문장을 EXPLAIN 하는 유저가 문장을 실행하는 유저와 다른 경우. 2명의 유져 같은 데이타베이스의 다른 오브젝트를 가리키고 있으면, 다른 실행 계획이 발생합니다.
3. 2 개의 조작간에 schema가 변경되었을 경우(많게는 색인의 변경).
2.코스트의 서로 틀림
——————
schema가 같아도 코스트가 다른 경우에 옵티마이져는 다른 실행 계획을 선택할 가능성이 있습니다. 코스트에 영향을 주는 몇개의 요인에는 다음의 것이 있습니다.
1. 데이터량과 통계
2. 바인드 변수의 형태
3. 초기화 파라미터(글로벌 설정 또는 세션·레벨로의 설정)
배제행수의 최소화
EXPLAIN PLAN 를 조사하는 것으로, 다음의 경우의 배제행수를 확인할 수 있습니다.
전표 스캔
선택성이 없는 레인지·스캔
지연한 술어 필터
잘못된 결합 순서
지연한 필터 처리
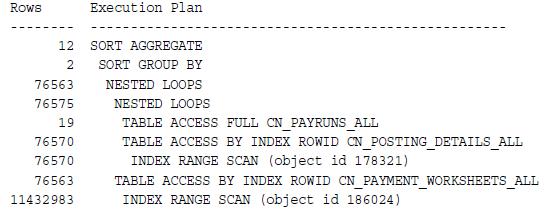
예를 들어, 다음의 EXPLAIN PLAN에서는 마지막 스텝은 매우 선택성이 없는 레인지·스캔 입니다.이 레인지·스캔은 76563 회 실행되어 11432983 행에 액세스 해, 액세스 한 행의 99 퍼센트를 배제해 76563 행을 보관 유지합니다.11432983 행에 액세스 한 결과 필요한 행이 76563 행뿐이라고 판별된 이유에 대해서 생각합니다.
예 9-1 EXPLAIN PLAN 내의 배제행수의 확인
실행 계획 이외의 고려사항
——————————————-
실행 계획의 조작만으로는 잘 조정된 문장과 잘 기능하지 않는 문장을 구별할 수 없습니다. 예를들어 문장에 의한 색인의 사용이 EXPLAIN PLAN 출력으로 나타났다고 해도, 그 문장이 효율적으로 기능한다라고 단정 할수 없다. 인덱스는 매우 비효율적인 경우도 있습니다. 이 경우, 다음을 조사할 필요가 있습니다.
사용되는 색인의 열
그 색인의 선택성(액세스 되는 표의 일부)
따라서 EXPLAIN PLAN 로 액세스 계획을 판단해 나중에 테스트에 의해서 그것이 최적의 계획인 것을 확인하는 것이 가장 좋은 방법입니다. 계획을 평가할 때는 문장의 정확한 리소스 사용량을 조사한다. Oracle Trace 또는 SQL 트레이스 기능과 TKPROF 를 사용해 개개의 SQL 문의 퍼포먼스를 조사해야 한다.
———————————————-
■ PLAN_TABLE 출력표의 작성
———————————————-
EXPLAIN PLAN 문을 발행하기 전에 출력 결과를 넣을 테이블이 필요합니다. PLAN_TABLE는 EXPLAIN PLAN 문이 실행 계획에 대해 기술하고 있는 행을 삽입하는 디폴트의 샘플 출력 테이블 입니다. SQL 스크립트 UTLXPLAN.SQL를 사용해 사용하고 있는 schema내에 PLAN_TABLE 를 작성한다. 이 스크립트의 정확한 이름과 위치는, 사용하는 OS에 따라서 다릅니다. 이 스크립트는 UNIX 상에서는 $ORACLE_HOME/rdbms/admin 디렉토리에 있습니다.
SQL> CONNECT HR/your_password SQL> @$ORACLE_HOME/RDBMS/ADMIN/UTLXPLAN.SQL Table created.
데이타베이스의 버젼을 갱신했을 경우는 열이 변경될 가능성이 있기 때문에 PLAN_TABLE 테이블을 삭제하고 재작성하는 것을 추천합니다. 테이블을 지정하는 경우는 스크립트의 실행이 실패하거나 TKPROF가 실패하는 경우가 있습니다.
다른 이름의 출력 테애블이필요한 경우는 PLAN_TABLE를 작성해 RENAME SQL문으로 그 이름을 변경 합니다.
———————————————-
■ EXPLAIN PLAN 의 실행
———————————————-
SQL문을 EXPLAIN 하는 경우는 다음을 사용합니다.
EXPLAIN PLAN FOR SQL_Statement
예)
EXPLAIN PLAN FOR SELECT last_name FROM employees;
계획을 EXPLAIN한 것이 PLAN_TABLE 테이블에 삽입됩니다. PLAN_TABLE 로부터 실행 계획을 선택할 수 있게 됩니다. 이것은 PLAN_TABLE 내에 다른 계획이 없는 경우나 마지막 문장만을 보는 경우에 편리합니다.
EXPLAIN PLAN 로의 문장의 지정
복수의 문장이 있을 때는 문장의 식별자를 지정해 그 식별자로 특정의 실행 계획을 식별할수 있다. SET STATEMENT ID를 사용하기 전에 그 문장과 같은 식별자를 가지는 기존의 행을 삭제한다.
예) STATEMENT ID를 사용한 EXPLAIN PLAN 의 사용 방법
EXPLAIN PLAN SET STATEMENT_ID = \'bad1\' FOR SELECT last_name FROM employees;
EXPLAIN PLAN에서 다른 테이블의 지정
INTO 구를 지정하면 다른 테이블을 지정할 수 있습니다.
예) INTO 구로의 EXPLAIN PLAN 의 사용 방법
EXPLAIN PLAN INTO my_plan_table FOR SELECT last_name FROM employees;
INTO 구를 사용하는 경우라도 문장의 식별자를 지정할 수 있습니다.
예)
EXPLAIN PLAN INTO my_plan_table SET STATEMENT_ID = \'bad1\' FOR SELECT last_name FROM employees;
———————————–
■ PLAN_TABLE 출력의 표시
———————————–
계획을 EXPLAIN 한 후 Oracle로부터 제공되는 2 개의 스크립트를 사용해 최신의 PLAN TABLE 출력을 표시합니다.
UTLXPLS.SQL – 시리얼 처리를 위한 PLAN TABLE 출력을 표시합니다.
UTLXPLP.SQL – 패러렐 실행열을 가지는 PLAN TABLE 출력을 표시합니다.
문장의 식별자를 지정했을 경우는 PLAN_TABLE를 문의하기 위한 독자적인 스크립트를 쓰는 것이 가능합니다. 다음에 예를 나타냅니다.
START WITH ID = 0 및 STATEMENT_ID 를 지정합니다.
CONNECT BY 구를 사용해 부모로부터 자식에게 트리를 이동합니다. 결합 키는, STATEMENT_ID = PRIOR STATEMENT_ID 와 PARENT_ID = PRIOR ID 입니다.
유사열LEVEL(CONNECT BY 에 관련지을 수 있고 있다)를 사용해 자식를 인덴트 섬
SELECT cardinality "Rows",
lpad(' ',level-1)||operation||' '||
options||' '||object_name "Plan"
FROM PLAN_TABLE
CONNECT BY prior id = parent_id
AND prior statement_id = statement_id
START WITH id = 0
AND statement_id = 'bad1'
ORDER BY id;
Rows Plan
------- ----------------------------------------
SELECT STATEMENT
TABLE ACCESS FULL EMPLOYEES
Rows열의 NULL은 옵티마이져가 테이블 통계를 가지고 있지 않은 것을 나타냅니다. 테이블을 ANALYZE 하면, 다음의 내용이 표시됩니다.
Rows Plan ------- ---------------------------------------- 16957 SELECT STATEMENT 16957 TABLE ACCESS FULL EMPLOYEES
COST도 선택할 수 있습니다. 이것은 실행 계획을 비교하는 경우나 옵티마이져가 복수의 안으로부터 있는 실행 계획을 선택한 이유를 이해하는 경우에 편리합니다.
참고 : EXPLAIN PLAN의 사용방법
